


What testing and integration of a subgraph in a DApp involve
In my previous article about blockchain data indexing I began exploring the creation and deployment of a subgraph with The Graph.
The testing and integration of a subgraph in a DApp would be the next natural step in the process: it consists of validating the subgraph's entities and mappings as a prerequisite to integrating the subgraph endpoint into the DApp that will consume the available data.
Subgraph testing
Once we have the subgraph deployed and indexed in Subgraph Studio, The Graph's testing environment, we can run the first queries very easily via the "playground".
It is an environment accessible from the dashboard that allows composing queries in GraphQL to retrieve live data from the subgraph.
GraphQL is a language standard and a server-side runtime that allows clients (APIs) to obtain complex datasets through a single endpoint.
The following image shows an example of using the playground:
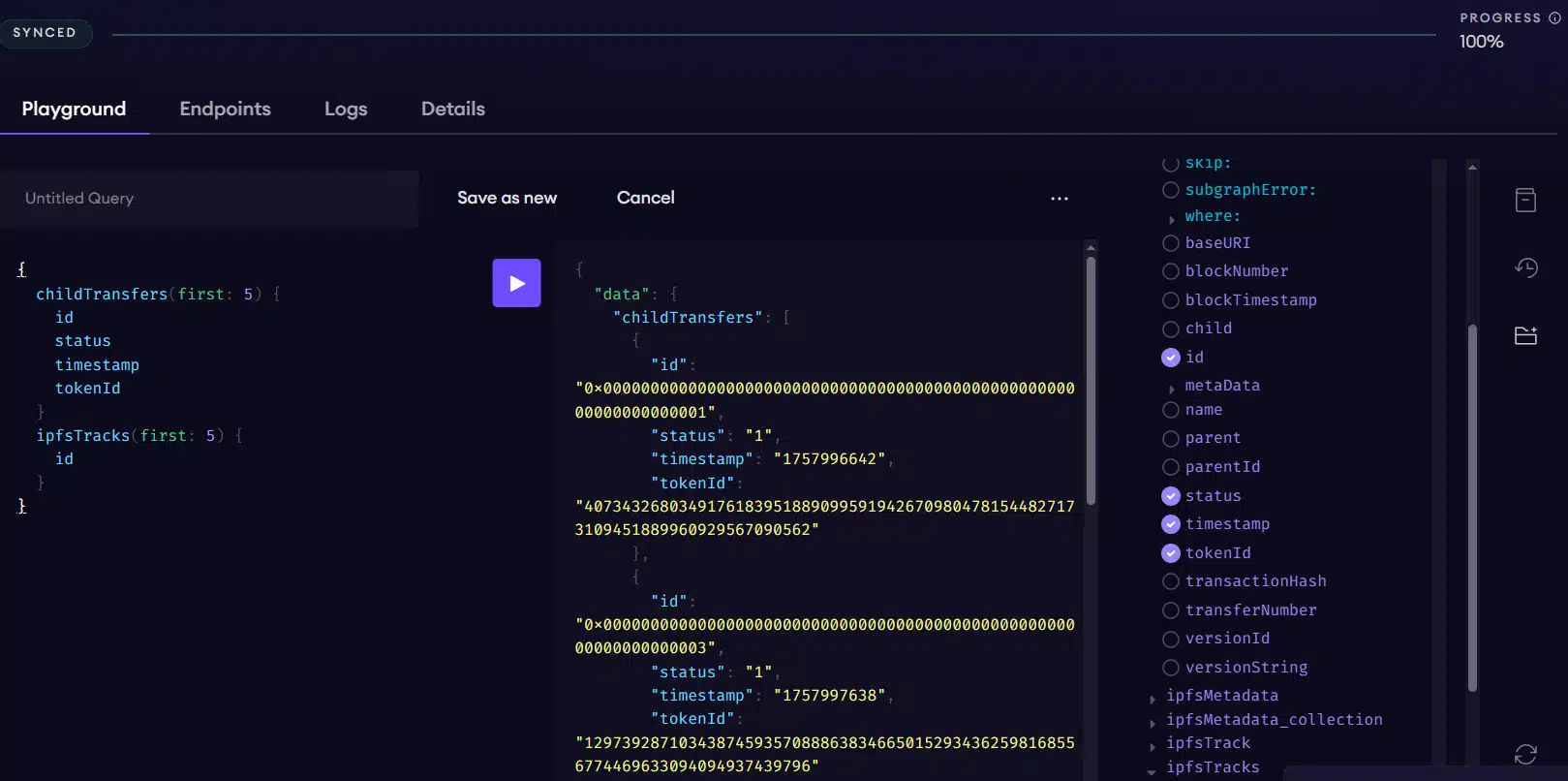
This illustrates the use of the GraphiQL explorer, an interface that lets you compose the client's query by selecting the available elements.
The generated query can be used directly in the DApp's source code files to integrate access to the same data.
Another useful tool to test and debug a subgraph would be using the logging API within The Graph's AssemblyScript API. It allows logging information in the subgraph mapping files, using various levels, so it can be viewed from Subgraph Studio or from Graph Explorer.
It is illustrated with the following code snippet
import { log } from "@graphprotocol/graph-ts";
const transferNumber = event.params.transferNumber;
const idBytes = bigIntTo32Bytes(transferNumber);
log.info('Adding new ChildTransfer event for ID: {} {}', [transferNumber.toString(), idBytes.toHexString()]);
let entity = new ChildTransfer(idBytes);
Integrating the subgraph into the DApp
Once the subgraph has been tested and debugged, it would be possible to integrate the consumption of the indexed data into the DApp.
There are several alternatives with The Graph. For its versatility and simplicity, below we cover the use of the graph-client, the project's own client. However, other options such as Apollo Client or URQL are also easily integrable.
The first step is to install the client's CLI as a development dependency, to later generate the production files:
yarn add -D @graphprotocol/client-cli
You should create a ".graphclientrc.yml" file where you declare the URL of the subgraph's development endpoint (it can be obtained through the Subgraph Studio portal):
sources:
- name: my-subgraph
handler:
graphql:
endpoint: https://api.studio.thegraph.com/query/...
retry: 1
timeout: 5000
transforms:
- autoPagination:
validateSchema: false
limitOfRecords: 1000
From here the CLI is invoked to automatically create the artifacts that allow interacting with the subgraph from the DApp:
yarn graphclient build
The artifact structure is created in the ".graphclient" directory.
It is important to note that whenever any configuration in the ".graphclientrc.yml" file changes, the artifacts must be regenerated.
To consume data from the subgraph in the DApp you must import the "execute" function: an asynchronous method that allows executing GraphQL queries by supplying the appropriate parameters:
import { execute } from '.graphclient/index.js';
import { gql } from 'graphql-request'
const childTransferQuery = gql`
query MyQuery($parent: Bytes, $parentId: BigInt) {
childTransfers(where: {parent: $parent, parentId: $parentId}
orderBy: id,
orderDirection: desc
first: 3000)
{
id
status
timestamp
tokenId
}
}
`
let childTransfer = await execute(childTransferQuery,
{
parent: parent,
parentId: `${parentId}`
}
);
Advanced client-side options
The "graph-client" presents some inherent advantages in its implementation. They are generally configured in the ".graphclientrc.yml" file (see examples in the one provided earlier). The following two stand out:
- Fetch strategies: you can define the maximum retries on error, the maximum timeout and the use of multiple endpoints in redundant mode.
- Autopagination: the maximum number of results to retrieve in a query is limited in The Graph to 1000. To solve this you can manually paginate results using "first/skip" or a filter (cursor filtering) or use the autopagination function that handles it automatically. It is important to note that despite this, there is a maximum limit of 5000 results in an autopaginated query, requiring manual pagination by filtering if more return values are needed.
Off-chain data indexing
Another utility that an indexer provides is the possibility of mixing data generated off-chain (off-chain). The Graph in its recent updates provides the mechanism of data sources to access off-chain data asynchronously, without affecting the normal pace of indexing on-chain data.
One of the most common data sources is IPFS, covering among other use cases the typical scenario of indexing each NFT with its metadata.
The basic definitions for this use case are outlined below:
#schema.graphql file
type ChildTransfer @entity(immutable: true) {
id: Bytes!
metaData: IpfsMetadata # 0 or 1 IpfsMetadata
tokenId: BigInt! # uint256
timestamp: BigInt! # uint256
status: BigInt! # uint256
}
type IpfsMetadata @entity(immutable: true) {
id: Bytes!
metaData: String!
}
#subgraph.yaml
templates:
- name: IpfsMetadata
kind: file/ipfs
mapping:
apiVersion: 0.0.9
language: wasm/assemblyscript
entities:
- IpfsMetadata
abis:
- name: MembershipManager
file: ./abis/MembershipManager.json
handler: handleIpfsContent
file: ./src/membership-manager.ts
# event handler in mappings file
// If the baseURI starts with "ipfs://", fetch metadata from IPFS
if(entity.baseURI.startsWith("ipfs://")) {
// Extract the CID from the baseURI
let hash = entity.baseURI.substring(7, entity.baseURI.length);
// Link the IpfsMetadata entity
entity.metaData = Bytes.fromUTF8(hash);
// Create a new dynamic data source for the IpfsMetadata template
IpfsMetadataTemplate.create(hash);
}
# file datasource handler in mapping file
export function handleIpfsContent(content: Bytes): void {
let hash = dataSource.stringParam();
log.warning('Handle metadata from: {}', [hash]);
// link the on-chain data with the off-chain retrieved content
let ipfs = new IpfsMetadata(Bytes.fromUTF8(hash));
ipfs.metaData = content.toString();
ipfs.save();
}
Conclusion: accessing structured blockchain data from DApps
The consumption of structured blockchain data from a DApp is an achievable task using indexers.
This article has presented some keys that allow fine-tuning a subgraph deployed in The Graph using the Graph Studio tool.
Subsequently, accessing that data from a decentralized application can be achieved using some of the client libraries available for developers.
The project's own library positions itself as one of the most versatile and easiest to use, with advanced features such as autopagination to retrieve large result sets.
In the next article I will finish the analysis of The Graph platform covering aspects such as best practices in building the subgraph and its move to production on the decentralized network.
Have you used any of the advanced features in The Graph to index your smart contract data? Do you mix on-chain data with off-chain information? Share your experiences!
If you need to consume structured data from your DApp and don't know how to obtain the information, I can help you integrate a subgraph into your project. Contact me and we'll analyze your case together. Best regards!

